Unusual targets
Try prompts such as "right vestibular schwannoma", "aortic arch", "aneurysm", or "portal vein" when a fixed-class model does not fit.
VoxTell is a 3D vision-language segmentation model. In MedSeg, it is useful when you want a candidate mask for a target that is easier to describe in text than to find in a fixed model menu.
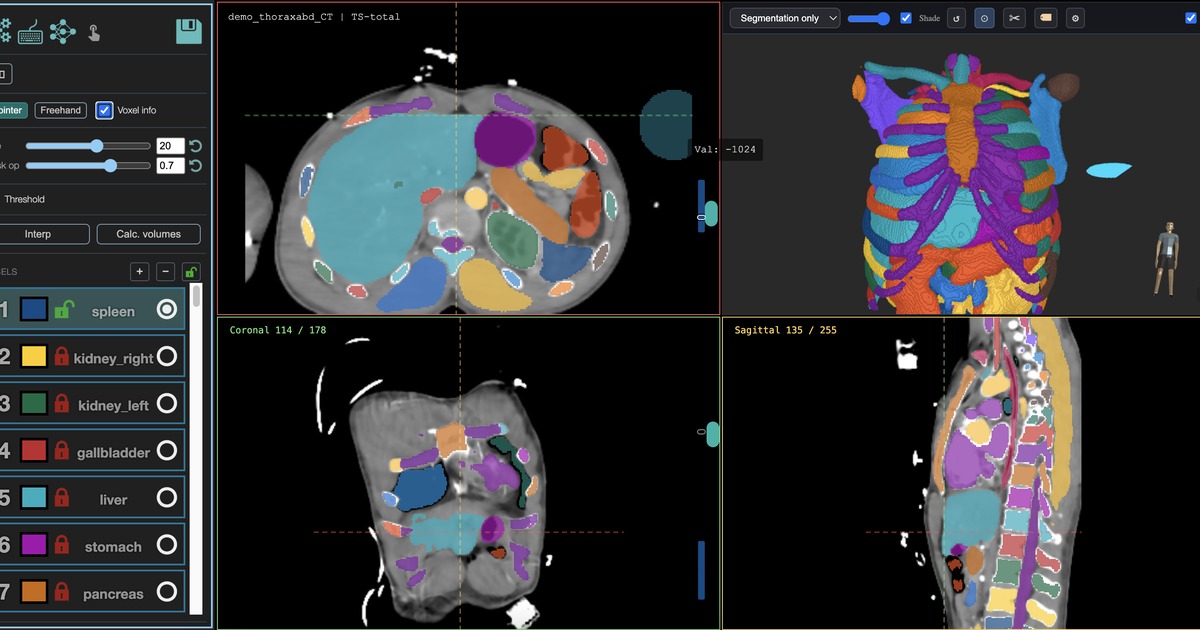
This silent demo shows the idea: type the target, run the model, and review the returned segmentation as a normal MedSeg mask.
VoxTell is best treated as fast candidate-mask generation for research, not as a final unchecked annotation.
Try prompts such as "right vestibular schwannoma", "aortic arch", "aneurysm", or "portal vein" when a fixed-class model does not fit.
Use text prompts to quickly test whether a structure or lesion is separable before committing to manual labels or custom training.
Generate a rough mask, correct it in the editor, then use the corrected result as training data for a repeatable model.
It is a project-view inference action, unlike nnInteractive, which lives inside the editor.
| Need | Best starting point | Why |
|---|---|---|
| Common whole-body CT anatomy | TotalSegmentator | Fixed labels are usually more predictable and easier to validate. |
| Target visible but hard to describe precisely | nnInteractive | Clicks and scribbles give direct spatial guidance. |
| Target can be described naturally | VoxTell | Free text can cover uncommon anatomy or pathology without choosing a predefined class. |
| Same target across many cases | Custom nnU-Net | Corrected labels become a repeatable project-specific model. |
VoxTell checkpoints are for the free/non-commercial research workflow unless separately licensed. Outputs are prompt-sensitive and should be reviewed. If the VoxTell entry is missing, the worker is offline, busy, or not enabled on that deployment.